
 https://erhankilic.org/wp-content/uploads/2023/08/Quick-sort-vs-Merge-sort.jpg
270
574
Erhan Kılıç
https://erhankilic.org/wp-content/uploads/2018/03/lastlogo.png
Erhan Kılıç2023-08-30 12:10:132025-09-23 21:41:31Birleştirme Sıralaması ve Hızlı Sıralama Rehberi: Böl ve Fethet Algoritmaları
https://erhankilic.org/wp-content/uploads/2023/08/Quick-sort-vs-Merge-sort.jpg
270
574
Erhan Kılıç
https://erhankilic.org/wp-content/uploads/2018/03/lastlogo.png
Erhan Kılıç2023-08-30 12:10:132025-09-23 21:41:31Birleştirme Sıralaması ve Hızlı Sıralama Rehberi: Böl ve Fethet Algoritmaları https://erhankilic.org/wp-content/uploads/2023/08/Binary_Search.jpg
345
984
Erhan Kılıç
https://erhankilic.org/wp-content/uploads/2018/03/lastlogo.png
Erhan Kılıç2023-08-29 21:53:272025-09-23 21:43:27İkili Arama Algoritması: Verimlilik
https://erhankilic.org/wp-content/uploads/2023/08/Binary_Search.jpg
345
984
Erhan Kılıç
https://erhankilic.org/wp-content/uploads/2018/03/lastlogo.png
Erhan Kılıç2023-08-29 21:53:272025-09-23 21:43:27İkili Arama Algoritması: Verimlilik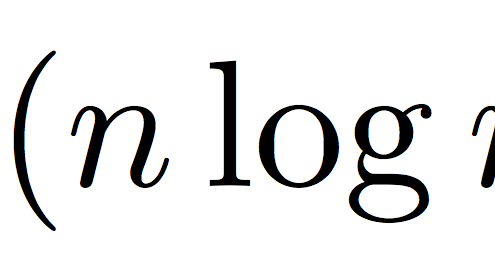 https://erhankilic.org/wp-content/uploads/2023/08/big-o-notation.png
268
877
Erhan Kılıç
https://erhankilic.org/wp-content/uploads/2018/03/lastlogo.png
Erhan Kılıç2023-08-28 12:25:112025-09-23 21:45:57Büyük O Notasyonu Rehberi: Algoritma Verimliliğini Anlama
https://erhankilic.org/wp-content/uploads/2023/08/big-o-notation.png
268
877
Erhan Kılıç
https://erhankilic.org/wp-content/uploads/2018/03/lastlogo.png
Erhan Kılıç2023-08-28 12:25:112025-09-23 21:45:57Büyük O Notasyonu Rehberi: Algoritma Verimliliğini Anlama https://erhankilic.org/wp-content/uploads/2023/08/Bubble-Sort-3.png
900
1600
Erhan Kılıç
https://erhankilic.org/wp-content/uploads/2018/03/lastlogo.png
Erhan Kılıç2023-08-27 19:47:352025-09-23 21:47:42Kabarcık Sıralaması Algoritması: Sıralamanın Basitliği
https://erhankilic.org/wp-content/uploads/2023/08/Bubble-Sort-3.png
900
1600
Erhan Kılıç
https://erhankilic.org/wp-content/uploads/2018/03/lastlogo.png
Erhan Kılıç2023-08-27 19:47:352025-09-23 21:47:42Kabarcık Sıralaması Algoritması: Sıralamanın Basitliği https://erhankilic.org/wp-content/uploads/2023/08/algorithms.webp
296
740
Erhan Kılıç
https://erhankilic.org/wp-content/uploads/2018/03/lastlogo.png
Erhan Kılıç2023-08-25 15:38:092025-09-23 21:50:15Algoritma: Mantık ve Verimlilik Yolculuğu
https://erhankilic.org/wp-content/uploads/2023/08/algorithms.webp
296
740
Erhan Kılıç
https://erhankilic.org/wp-content/uploads/2018/03/lastlogo.png
Erhan Kılıç2023-08-25 15:38:092025-09-23 21:50:15Algoritma: Mantık ve Verimlilik Yolculuğu